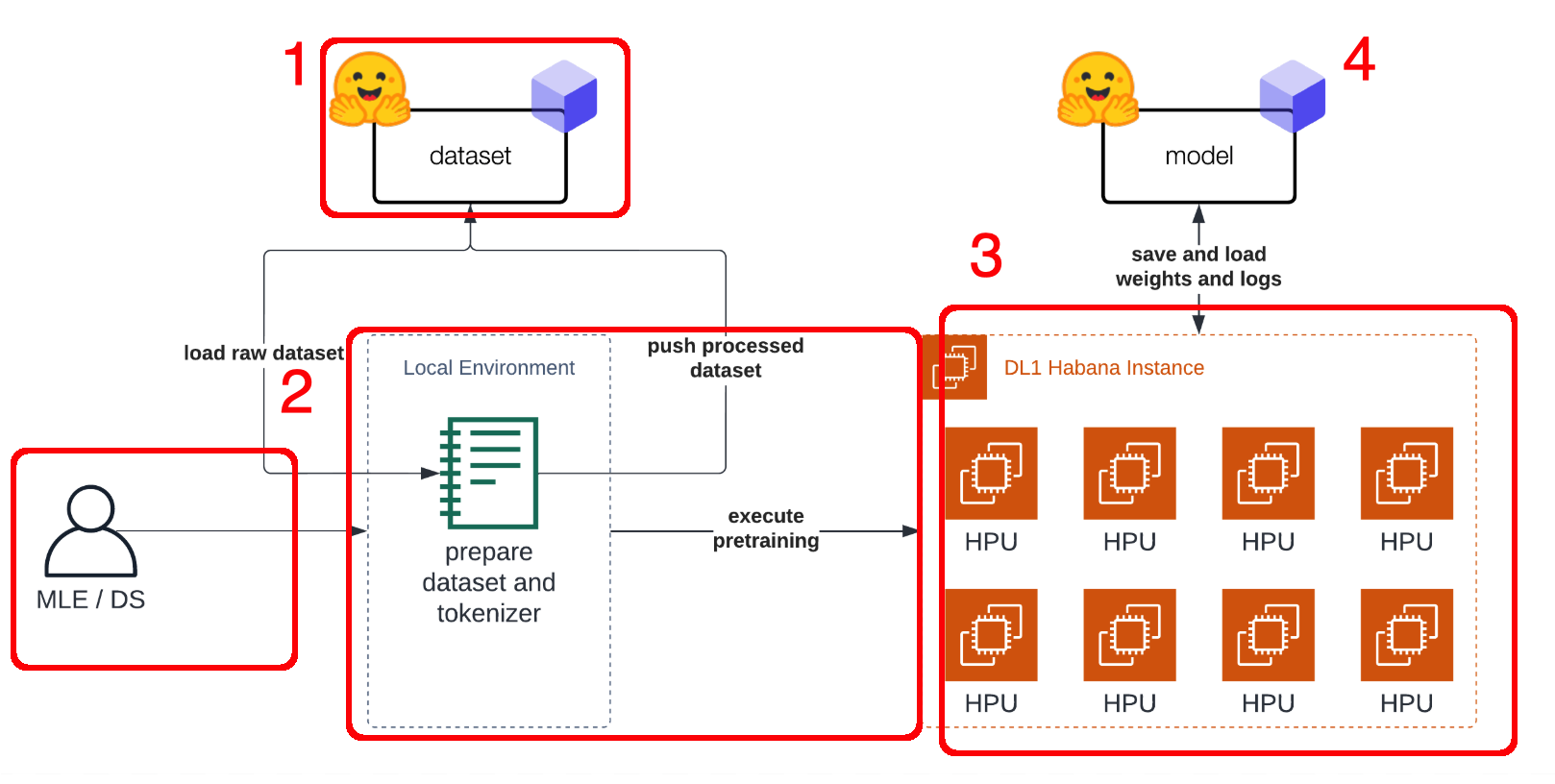
traditional model building process
Open Source LLM? Really? (DeepSeek R1 Example)
Simplified Edition
Open Source vs. Non-Open Source LLMs: Clearing Up the Confusion
The release of DeepSeek R1 sparked excitement across the tech world. Some have called it “open source,” but the term can mean different things when it comes to Large Language Models (LLMs). Below, we break down what “open source” typically means in software, and how it looks a bit different in the LLM world.
1. Traditional Open Source vs. “Open” LLMs
In traditional open source software:
- The source code is publicly available for viewing, modifying, and distributing.
- You can also see how it’s compiled and what dependencies it uses.
For “open source” LLMs:
- Their trained weights might be publicly shared under a license that allows you to download, run, or fine-tune the model.
- However, the training data and training scripts are often kept private.
- Without that information, you can’t fully recreate or retrain the model from scratch.
2. Why Having Just the Weights Isn’t Enough
- Proprietary or Private Datasets
- LLMs usually learn from massive datasets that might not be available publicly (due to licensing or NDAs).
- Simply having the final weights doesn’t reveal which data the model was trained on.
- This makes replicating or altering the original training process very difficult.
- Training Software and Scripts
- Organizations sometimes share only parts of the code used for training.
- The complete “recipe” (including special configs, distributed-training techniques, or hyperparameters) might be missing.
- Without those, recreating results is nearly impossible.
- Infrastructure Requirements
- Modern LLMs need powerful (and expensive) GPU clusters or specialized hardware to train.
- Even if you have the same data and code, you might not have the multi-million-dollar compute setup.
- This creates a major practical barrier for reproducing “open” models.
Basically, we are missing here 1 , 2 and 3 on the pictures , including the smart ML / DS engineers haha.
traditional model building process
3. The DeepSeek R1 Release and the “Open” Hype
DeepSeek R1 launched with lots of buzz and was labeled by some as an open-source LLM. In reality:
- The weights were shared under a permissive license.
- The training data is either under NDA or proprietary.
- The training details (like hyperparameters, custom code) remain undisclosed.
Yes, you can download and fine-tune DeepSeek R1. But you can’t fully recreate its training or verify the exact steps that produced those weights. So it’s more accurate to call DeepSeek R1 a “model with openly available weights” rather than a completely open source project.
4. Implications for the LLM Community
- Innovation and Transparency
- Released weights help developers build apps or fine-tune for their own needs.
- But hidden data selection or cleaning processes mean unseen biases might remain.
- Reproducibility
- True open source in machine learning would let others retrain and get similar results.
- Without full data, code, and environment details, that’s virtually impossible.
- Commercial vs. Community
- Companies may share parts of their model for community use or research while keeping key components private.
- Some academic/nonprofit labs aim for full transparency but usually face funding limits for large-scale training.
5. How to Build (and Share) LLMs More Transparently
- Provide All Training Artifacts
- Share data sources (where possible), data preprocessing steps, and licensing details.
- Release the training scripts, hyperparameters, and environment configurations.
- Document the Infrastructure
- Clearly describe the hardware setup, memory usage, and any unique system configurations.
- While it won’t solve cost issues, it at least helps others understand your approach.
- Use Clear Licensing
- If it’s truly open source, use recognized licenses (e.g., Apache 2.0, MIT) that grant reuse and distribution rights.
- If there are restrictions (like research-only), be explicit.
- Encourage Community Contributions
- Permit users to view and modify training code.
- Offer discussion platforms (forums, GitHub issues) where people can give feedback or suggest improvements.
6. Conclusion
Simply being able to download and run LLM weights doesn’t make a model “fully open source.” True openness involves sharing everything—training data, code, infrastructure details—so anyone can replicate or deeply modify the model.
DeepSeek R1’s release is exciting, but we need to be clear on what “open” really means. By setting the right expectations, we keep AI research honest, transparent, and collaborative.
